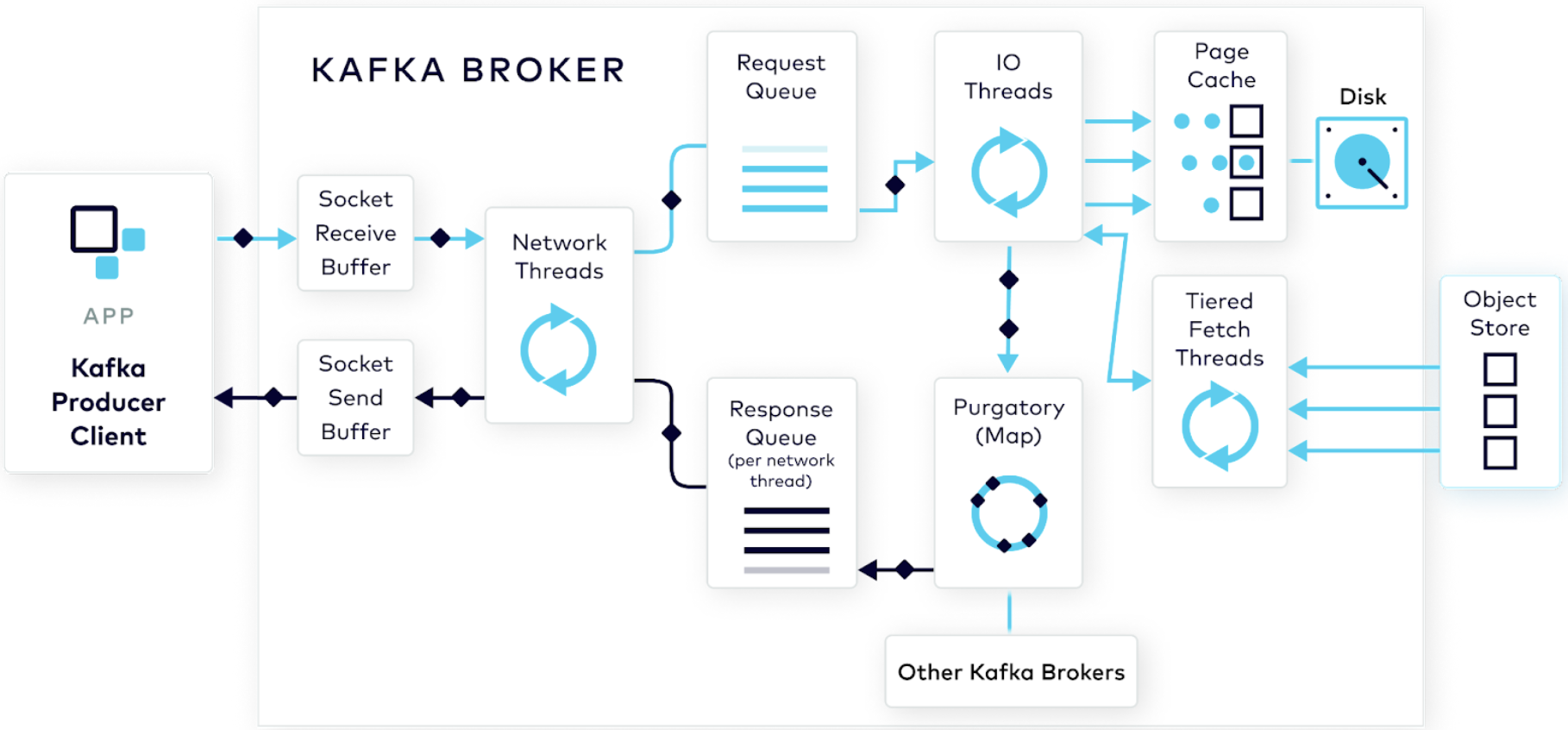
kafka-入门篇
1. 三大特性
| 特性 | 描述 | 保障机制 |
|---|---|---|
| 高性能 | 实现每秒百万级消息处理能力 | 顺序读写、Reactor多路复用、零拷贝、批量压缩传输 |
| 高并发 | 通过分布式设计支持大规模并发访问 | 分区与并行化、消费者组、异步处理与多线程 |
| 高可用 | 通过冗余机制保障服务不间断 | 多副本、Leader选举、ISR、ACK |
2. 三大功能
| 功能 | 描述 | 应用场景 |
|---|---|---|
| 异步 | 生产者发送消息后无需等待消费者处理,通过非阻塞通信提高系统吞吐量和响应速度 | 文件处理任务、用户注册后异步发送邮件/短信 |
| 解耦 | 通过发布-订阅模型分离生产者和消费者,消除系统组件间的耦合 | 事件驱动系统 |
| 削峰 | 利用消息队列缓冲突发流量,平滑处理生产与消费速率差异,防止下游系统因瞬时高并发崩溃 | 电商秒杀/大促流量缓冲 |
3.重要概念
3.1 核心组件
| 概念 | 简介 |
|---|---|
| Producer (生产者) | 向 Broker 发送消息的客户端,支持异步批量发送、数据压缩及自定义分区策略(如 Key 哈希或轮询) |
| Consumer (消费者) | 从 Broker 读取消息的客户端,支持按分区顺序消费或回溯(Offset),基于 Pull 模式主动拉取数据 |
| Consumer Group (消费者组) | 多个消费者组成的逻辑单元,组内每个消费者负责消费不同分区的数据,以提高消费能力 组内消费者共享消费进度(Offset),每个分区仅由组内一个消费者消费 |
| Broker (物理节点) | 负责存储消息、处理读写请求及副本同步 一台物理机器就是一个 Broker,一个 Broker 可以容纳多个 Topic |
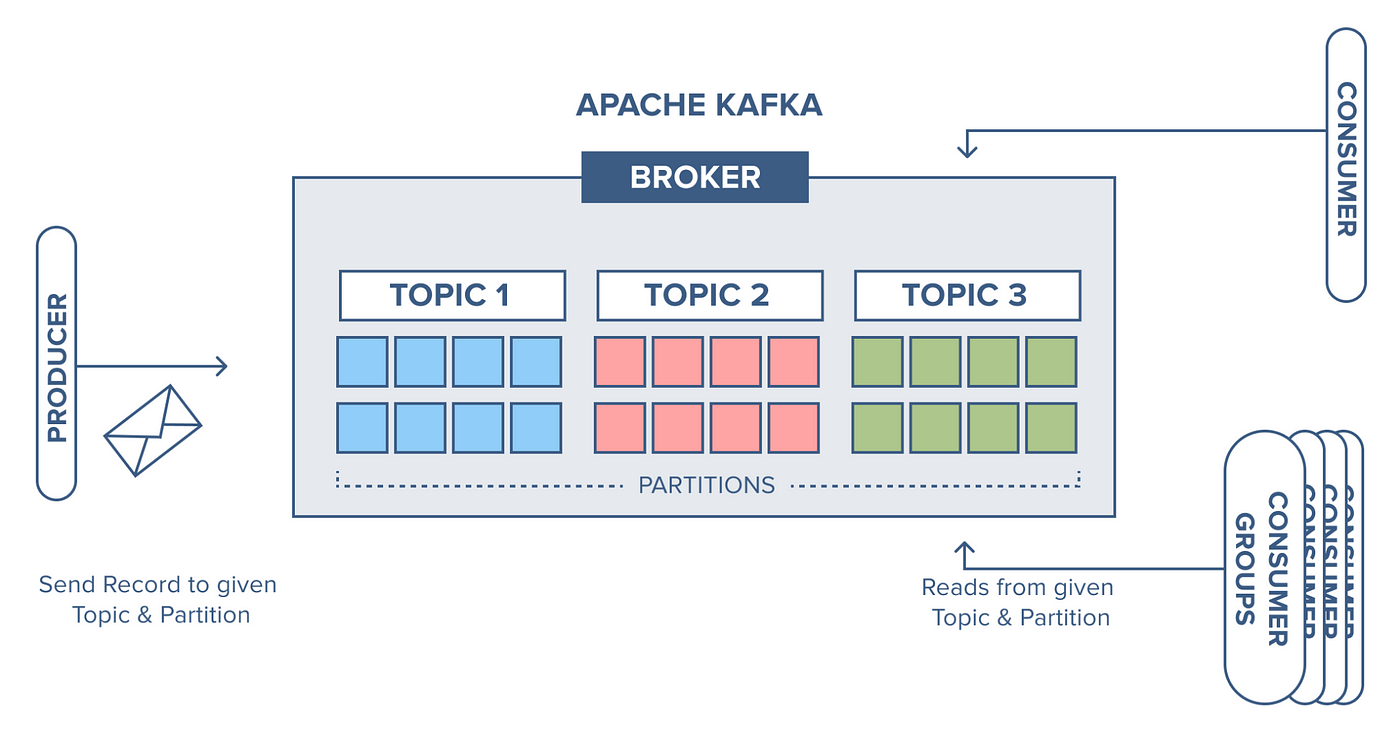
Producer
消息可靠性配置
- 性能优化:
- acks=0:不等待确认,最高吞吐但可能丢数据,适合日志采集等低可靠性场景。
- acks=1:仅 Leader 确认,默认值,Leader 副本写入即响应,均衡吞吐与可靠性。
- acks=all:全副本确认,需所有 ISR 副本确认,确保数据不丢失,适合金融等高要求场景。
- 重试机制:设置 retries,配合
retry.backoff.ms避免瞬态故障导致消息丢失
- 性能优化:
性能优化
- 批量发送:启用
producer.type=async,调整batch.size(如 32KB)和linger.ms(如 100ms)提升吞吐。 - 压缩策略:选用
compression.type=lz4或snappy,减少网络传输开销。 - 缓冲区管理:增大
buffer.memory(如 64MB)防止发送阻塞
- 批量发送:启用
序列化与分区
- 序列化器选择:明确指定
key.serializer和value.serializer,避免默认编码导致乱码。 - 自定义分区器:根据业务逻辑实现
Partitioner,避免数据倾斜(如按 Key 哈希分配)
- 序列化器选择:明确指定
Consumer & Consumer Group
- 组管理与容错
- 消费者数量:
消费者数 ≤ 分区数,超过时部分消费者闲置,建议消费者数 = 分区数以最大化吞吐
- 消费者数量:
- Rebalance
- 触发条件:当消费者增减、分区数变化时,Kafka会触发一次重平衡操作,重新分配分区给群组中的消费者
- 幂等消费
- 去重机制:结合业务唯一键(如订单号)或数据库乐观锁(版本号)处理重复消息
- 死信队列:将处理失败的消息转入独立 Topic,便于人工干预或异步重试
Broker
- 存储与性能
- 磁盘优化:使用 SSD 或多磁盘路径(log.dirs)提升 IO 性能
- 日志清理:配置 log.retention.hours=72 或 log.retention.bytes=1GB 自动清理旧数据
3.2 消息组织
| 概念 | 简介 |
|---|---|
| Message (消息) | 数据传输的基本单元,类似于数据库中的一条记录,每条消息由 键(Key)、值(Value)、时间戳(Timestamp) 和可选元数据组成 字节数组:消息本身是字节数组,无固定格式,支持任意类型数据(如 JSON); 键的作用:用于分区策略(如哈希分配),相同键的消息会被写入同一分区,保证顺序性; 持久化:消息被追加到分区日志文件末尾,不可修改或删除,仅按时间或大小策略清理; |
| Topic (主题) | 消息的逻辑分类单元,类似数据库表,可以理解为一个消息队列的名字,生产者和消费者通过 Topic 交互 |
| Partition (分区) | Topic 的物理分片,每个分区是一个有序、不可变的消息队列,分布在多个 Broker 上 有序性:同一分区内的消息严格按写入顺序存储和消费; 并行处理:多个分区允许消费者组内多个实例并行消费,提升吞吐量(如 10 分区的 Topic 可支持 10 倍并发); 副本机制:每个分区有 1 个 Leader(处理读写)和多个 Follower(同步备份),通过 ISR 机制(同步副本集)保障高可用。 分片存储:每个 Partition 对应一组 .log(数据文件)和 .index(索引文件),支持高效二分查找 |
| Offset (偏移量) | 消息在分区中的唯一位置标识,单调递增且不可变 消费定位:消费者通过 Offset 确定下次从何处开始消费,支持自动提交或手动提交记录Offset; 存放位置:早期Offset存储在ZooKeeper,v0.9 开始 Offset 存储在 Kafka 内置 Topic __consumer_offsets 中,支持高频写入和持久化; |
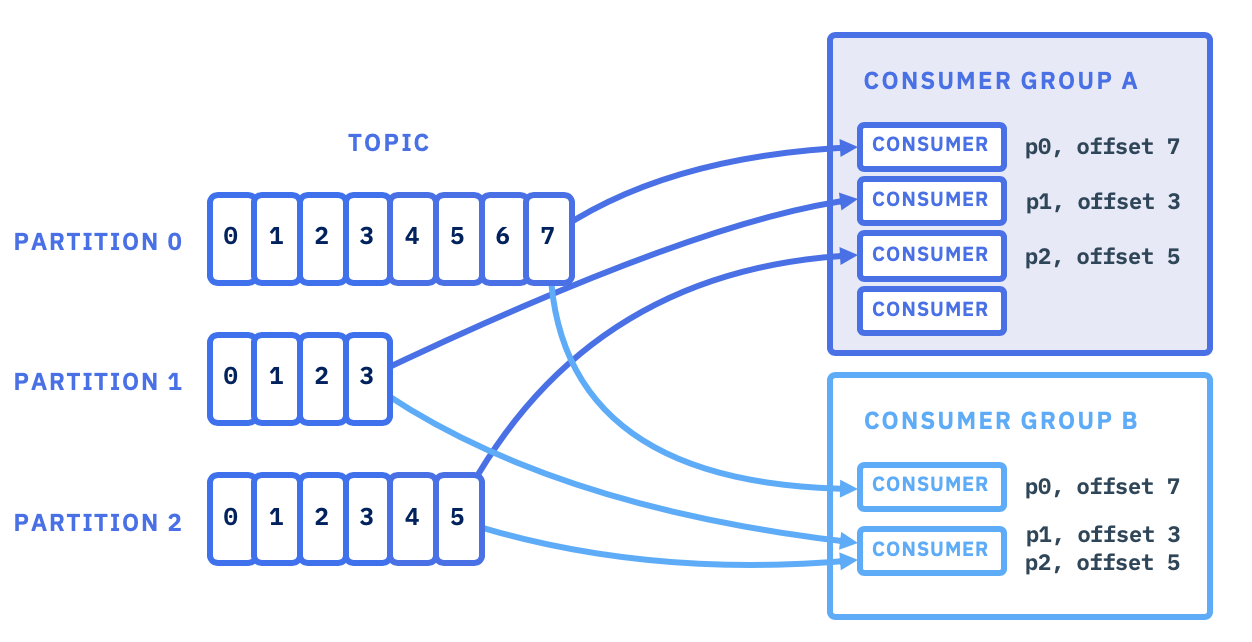
Message
- 顺序性与幂等处理
- 顺序性:
Kafka 仅保证同一分区内的消息顺序,跨分区的消息顺序无法保证。若业务需要严格顺序(如订单状态变更),需通过消息 Key 路由到同一分区 - 幂等性:生产者需开启
enable.idempotence=true,避免因网络重试导致重复消息;消费者需处理重复消费问题(如数据库去重或版本号校验)
- 顺序性:
- 消息体优化
- 大小限制:单条消息建议不超过 1MB,避免因大消息体导致磁盘 I/O 压力增大和网络传输延迟
- 异常处理机制
- 重试策略:生产端配置 retries 参数(建议 ≥3),消费端结合异步重试队列(如 Kafka 死信队列)处理失败消息
Topic
- 分区与副本规划
- 分区数:根据吞吐量需求设置,通常建议为 Broker 数量的整数倍(如 3 倍)。过多的分区会增加文件句柄和磁盘I/O压力以及内存占用
- 副本数:至少设置 3 副本(
replication.factor=3),结合min.insync.replicas=2提升容错能力
- 生命周期管理
- 数据保留策略:根据业务需求选择时间(
retention.ms)或大小(retention.bytes)策略,避免磁盘耗尽 - 清理策略:若需保留 Key 最新状态(如用户配置更新),启用
log.cleanup.policy=compact
- 数据保留策略:根据业务需求选择时间(
- 命名与分类
- 命名规范:Topic 名称需具有业务语义(如
order-events),避免使用泛化名称(如test)
- 命名规范:Topic 名称需具有业务语义(如
Partition
- 负载均衡与路由策略
- 均匀分配:通过 Key 哈希(默认)或轮询策略写入分区,避免单个分区数据倾斜导致积压。
- 动态扩容:增加分区时需同步扩展消费者组,否则新分区可能无消费者处理
Offset
- 提交策略
- 自动提交:设置
enable.auto.commit=true和auto.commit.interval.ms(默认 5 秒),适合低延迟场景,但可能导致重复消费。 - 手动提交:关闭自动提交,通过
commitSync()或commitAsync()精确控制提交时机(如批处理完成后),确保“至少一次”语义
- 自动提交:设置
3.3 副本机制
| 概念 | 简介 |
|---|---|
| Replica (副本) | 保障数据高可用性和容错性的核心设计,每个 Topic 的 Partition 可以配置多个副本,这些副本分布在不同的 Broker 上,形成冗余备份 |
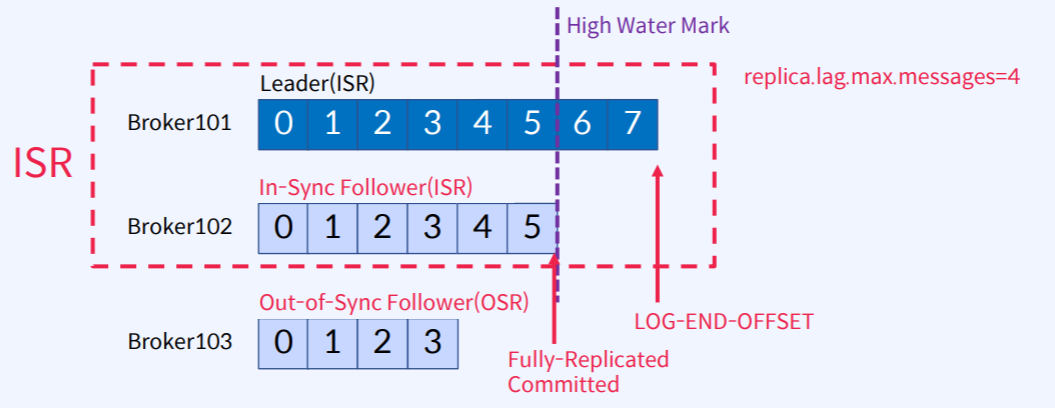
| ISR (In-Sync Replicas,同步副本集) | 动态维护的与 Leader 保持同步的副本集合,包含 Leader 自身和同步的 Follower 副本 |
| OSR (Out-of-Sync Replicas,非同步副本集) | 滞后于 Leader 的副本集合,与 ISR 共同构成分区的全量副本集合(AR,Assigned Replicas) |
| HW (High Watermark,高水位) | 标识已提交消息的最大偏移量,消费者仅能读取 HW 之前的消息。HW 由 ISR 中最小的 LEO 决定 |
| LEO (Log End Offset,日志末端偏移) | 当前分区最新消息的偏移量,反映副本的实时写入进度 |
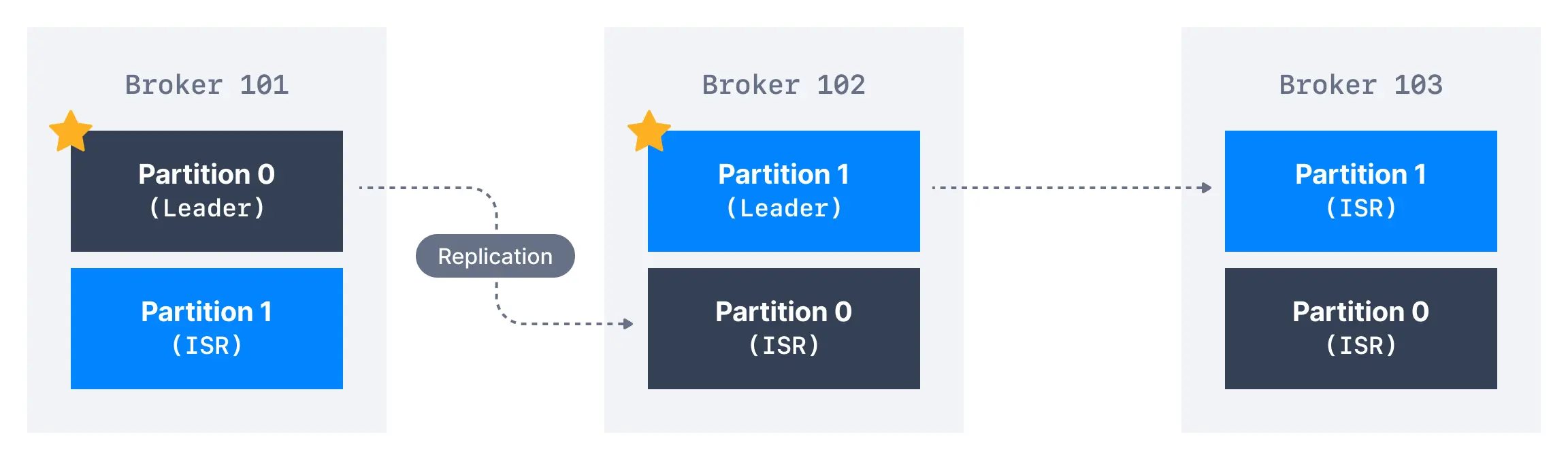
Replica
- 两类副本
- Leader:每个分区的唯一主副本,负责处理所有读写请求。生产者将消息写入 Leader,消费者从 Leader 读取消息
- Follower:从 Leader 异步拉取数据并同步到本地日志,不处理客户端请求。唯一任务是保持与 Leader 的数据同步,并在 Leader 故障时参与选举成为新 Leader
- Replication Factor 副本因子
- 表示每个分区的数据副本数量。例如,副本因子为 3 时,每个分区的数据会存储到 3 个不同 Broker 上
AR (ISR + OSR)
同步判定条件:Follower 副本需在
replica.lag.time.max.ms时间内追上 Leader 的日志偏移量(LEO),否则会被移出ISR(归入OSR),恢复同步后重新加入ISR
- 数据一致性:生产者在
acks=all模式下需等待 ISR 中所有副本确认写入,确保消息提交后不会丢失 - 故障容错:Leader 故障时,优先从 ISR 中选举新 Leader,避免数据不一致
- 数据一致性:生产者在
OSR
- 数据备份:OSR 副本可作为数据恢复的”最后防线”,当 ISR 副本全部故障时,尝试从 OSR 恢复数据
3.4 存储结构
逻辑结构
- Topic:逻辑上的消息分类单位
- Partition:
Kafka存储的基本物理单位,每个Topic被划分为多个Patition
物理结构
每个Partition对应一个独立的日志文件,消息按顺序追加写入
- 分区的意义
- 水平扩展:将数据分布到多个 Broker,提升并发处理能力。
- 顺序写入优化:仅追加写(Append-Only),充分利用磁盘顺序 I/O 的高性能
Segment (分段)
- 每个分区的日志被切分为多个 Segment 文件,避免单个文件过大(默认 1GB)
- 每个 Segment 包含:
.log文件:存储实际消息数据,按消息偏移量(Offset)顺序写入.index文件:稀疏索引,记录消息偏移量与物理位置的映射关系,加速查询.timeindex文件:基于时间戳的索引,支持按时间范围检索消息
- 分段示例
topic-name-0/
├── 00000000000000000000.log # 实际消息数据
├── 00000000000000000000.index # 稀疏矩阵
└── 00000000000000000000.timeindex # 基于时间戳的索引
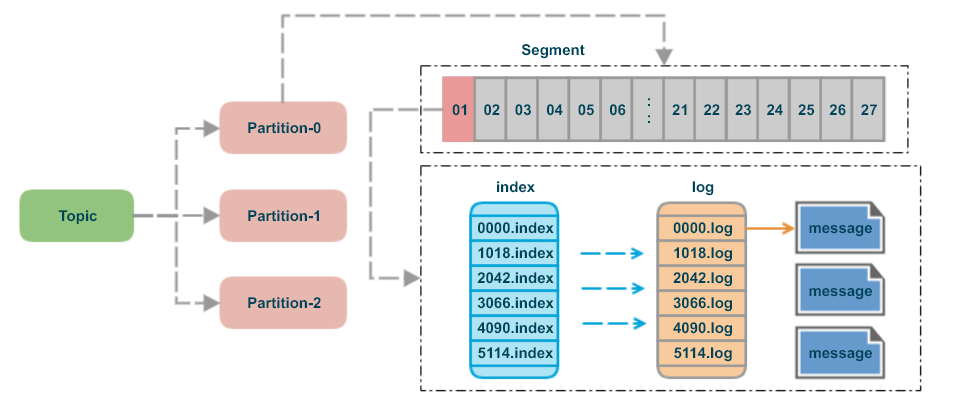
Index (索引)
- 稀疏索引设计
- 仅记录部分消息的偏移量(如每 100 条消息),通过二分查找快速定位目标消息所在的 Segment,再顺序扫描细化位置。
- 优点:减少索引文件大小,避免内存占用过高,同时兼顾查询效率

存储优化技术
顺序写入与页缓存(PageCache)
- 顺序写入:仅追加写日志文件,避免磁盘随机寻址,机械磁盘吞吐量可达数百 MB/s。
- 页缓存:利用操作系统缓存机制,将磁盘数据预读至内存,减少直接 I/O 操作。
零拷贝(Zero-Copy)
- 数据从磁盘文件直接传输到网络设备(NIC),绕过用户态与内核态多次拷贝,降低 CPU 开销与延迟。
日志清理机制
- 基于时间:自动删除超过保留时长(如 7 天)的 Segment。
- 基于空间:限制分区总大小,超出时删除旧数据。
- 日志压缩(Compaction):保留相同 Key 的最新 Value,适用于状态更新场景
3.5 元数据与协调服务
元数据
元数据是 Kafka 集群运行的基础信息,包括以下内容:
- 集群基础信息
- Broker 节点列表:记录所有 Broker 的 IP、端口、ID 及角色(如 Controller)。
- Topic 与 Partition 定义:每个 Topic 的分区数、副本分布(Leader/Follower)、ISR 列表(同步副本集)。
- 消费者组状态:Consumer Group 的成员信息、消费偏移量(Offset)及分区分配策略。
- 动态运行时数据
- Partition 的 Leader 信息:由协调服务动态维护,用于消息路由。
- 消费者偏移量 Offset 管理:记录消费者消费进度,确保故障恢复后从正确位置继续消费。
- 元数据存储方式
- ZooKeeper 模式(旧版):元数据存储在 ZooKeeper 的 /brokers、/consumers 等节点中。
- KRaft 模式(新版,Kafka 2.8+):元数据由 Kafka 自身通过 Raft 协议管理,存储在内部 Topic __cluster_metadata 中,不再依赖 ZooKeeper。
协调服务
协调服务负责维护元数据一致性及集群动态管理,核心功能如下:
- ZooKeeper 协调机制(旧版)
- Broker 注册与选举:Broker 启动时向 ZooKeeper 注册,通过临时节点(/brokers/ids)监控节点存活状态。Controller 节点(由 ZooKeeper 选举)负责分区 Leader 选举。
- 消费者组管理:消费者通过 ZooKeeper 协调分区分配(如 ConsumerRebalanceListener),Offset 默认存储在 ZooKeeper 的 /consumers 路径(Kafka 0.9 后改为内部 Topic __consumer_offsets)。
- 负载均衡:动态调整 Partition 分布,响应 Broker 增减或故障。
- KRaft 协调机制(新版)
- Raft 协议实现一致性:Controller 节点通过 Raft 协议选举 Leader,所有元数据变更需多数派确认后提交到日志(Log),确保多节点状态一致。
- 事件驱动架构:Broker 订阅 KRaft 日志,根据事件(如 Partition 分配变更)更新本地元数据缓存,实现最终一致性。
- 性能优化:KRaft 模式下,元数据操作吞吐量显著提升(如 200 万分区场景下性能优于 ZooKeeper),且运维复杂度降低。
4. 实验
4.1 环境搭建
通过 docker 快速启动 kafka 以及可视化操作平台,执行 docker-compose up -d
- 3个broker节点
- 1个zookeeper节点
- 1个kafka-ui节点
services:
zookeeper:
image: bitnami/zookeeper:3.8
container_name: zookeeper
ports:
- "2181:2181"
volumes:
- ./zookeeper:/bitnami/zookeeper
environment:
ALLOW_ANONYMOUS_LOGIN: "yes" # 允许匿名登录
networks:
- kafka_network
kafka01:
image: bitnami/kafka:3.6
container_name: kafka01
ports:
- "9092:9092"
volumes:
- ./kafka01:/bitnami/kafka
environment:
KAFKA_CFG_NODE_ID: 1 # Broker唯一标识符
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181 # 连接zookeeper集群
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://kafka01:9092 # Broker监听客户端请求的协议、地址和端口
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092 # 向客户端公布的访问地址
ALLOW_PLAINTEXT_LISTENER: "yes" # 允许使用未加密的PLAINTEXT协议
depends_on:
- zookeeper
networks:
- kafka_network
kafka02:
image: bitnami/kafka:3.6
container_name: kafka02
ports:
- "9093:9092"
volumes:
- ./kafka02:/bitnami/kafka
environment:
KAFKA_CFG_NODE_ID: 2
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://kafka02:9092
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092
ALLOW_PLAINTEXT_LISTENER: "yes"
depends_on:
- zookeeper
networks:
- kafka_network
kafka03:
image: bitnami/kafka:3.6
container_name: kafka03
ports:
- "9094:9092"
volumes:
- ./kafka03:/bitnami/kafka
environment:
KAFKA_CFG_NODE_ID: 3
KAFKA_CFG_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_CFG_ADVERTISED_LISTENERS: PLAINTEXT://kafka03:9092
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092
ALLOW_PLAINTEXT_LISTENER: "yes"
depends_on:
- zookeeper
networks:
- kafka_network
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
ports:
- "8080:8080"
environment:
DYNAMIC_CONFIG_ENABLED: 'true'
KAFKA_CLUSTERS_0_NAME: kafka-cluster
KAFKA_CLUSTERS_0_BOOTSTRAP_SERVERS: kafka01:9092,kafka02:9093,kafka03:9094 # 集群节点列表
depends_on:
- kafka01
- kafka02
- kafka03
networks:
- kafka_network
networks:
kafka_network:
driver: bridge
4.2 创建 Topic
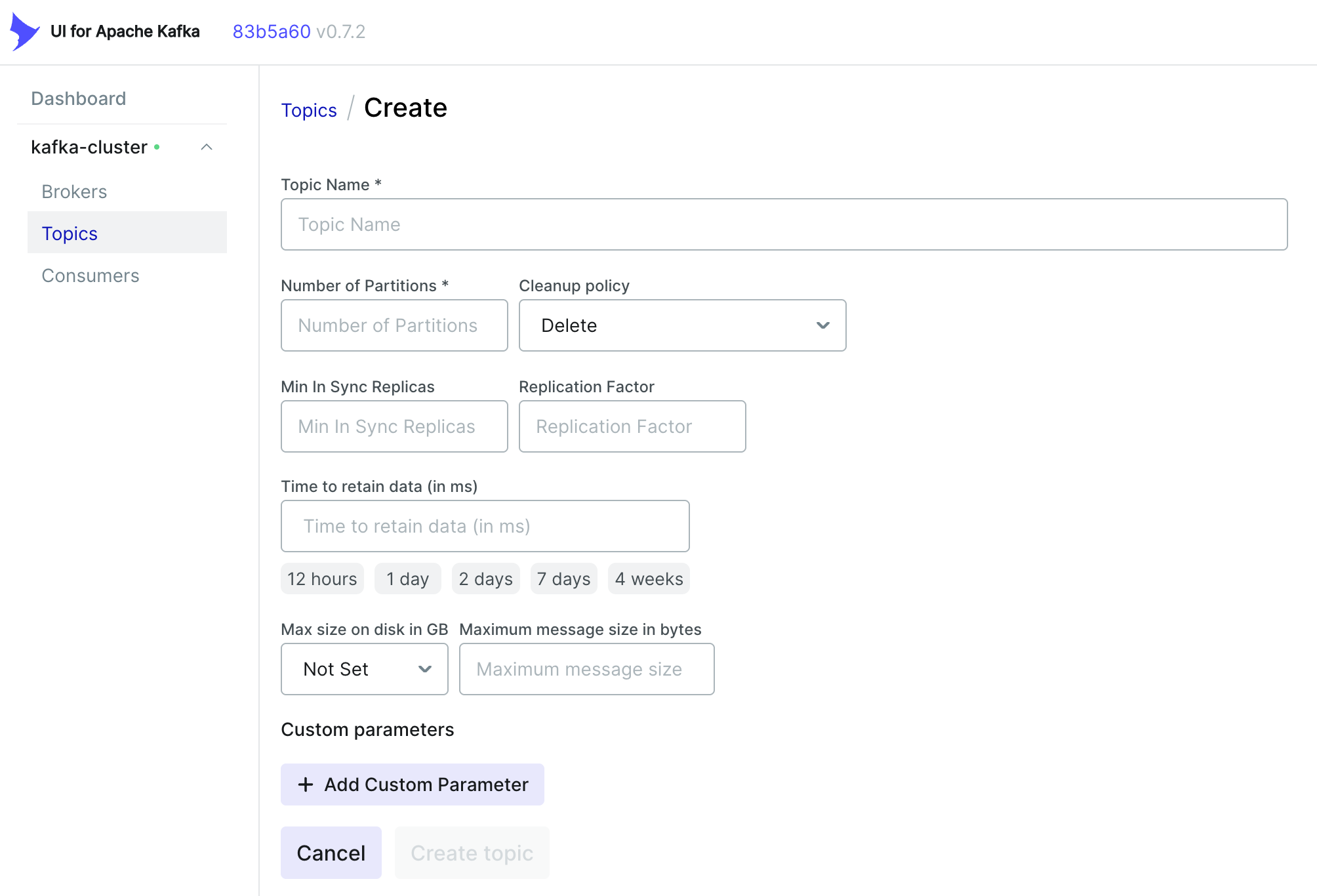
| 参数 | 说明 | 注意 |
|---|---|---|
| Topic Name | 主题名,用于区分不同的数据流 | 命名需清晰反映业务用途 |
| Number of Partitions | 分区数,分区数量决定数据并行处理能力,直接影响吞吐量上限 |
分区数应与消费者组内消费者数量匹配 分区过多会增加文件句柄和内存开销 |
| Cleanup policy | 控制过期数据的清理策略,支持delete(删除)和compact(压缩) |
1.delete策略:按时间(log.retention.hours)或大小(log.retention.bytes)删除旧 Segment 文件。默认保留 7 天,适用于日志类无状态数据。2. compact策略:保留每个 Key 的最新 Value,适合维护终态(如用户配置、账户余额)。需确保消息包含 Key,否则策略无效。3. 混合策略:delete + compact 可同时启用,兼顾压缩活跃数据与清理过期 Segment |
| Min In Sync Replicas | 生产者写入时需确认的最小同步副本数(ISR) | 建议设为 Replication Factor - 1(如副本因子为 3,则设为 2)若 ISR 数量不足,生产者会抛出 NotEnoughReplicasException |
| Replication Factor | 每个分区的副本数量,决定容错能力 | 生产环境推荐设为 3,容忍 2 个 Broker 故障 副本数不得超过集群 Broker 总数,否则 Topic 创建失败 |
| Time to retain data | 数据保留时间 | 删除策略下,Segment 文件按最大时间戳判断是否过期 |
| Max size on disk | Topic 最大存储容量 | 若总大小超限,优先删除最旧 Segment,但实际删除可能延迟 |
| Maximum message size in bytes | 单条消息最大大小(默认 1MB) | 若消息超限,生产者会抛出RecordTooLargeException |
- 副本数(4) > Broker数(3) ===> Topic 创建失败
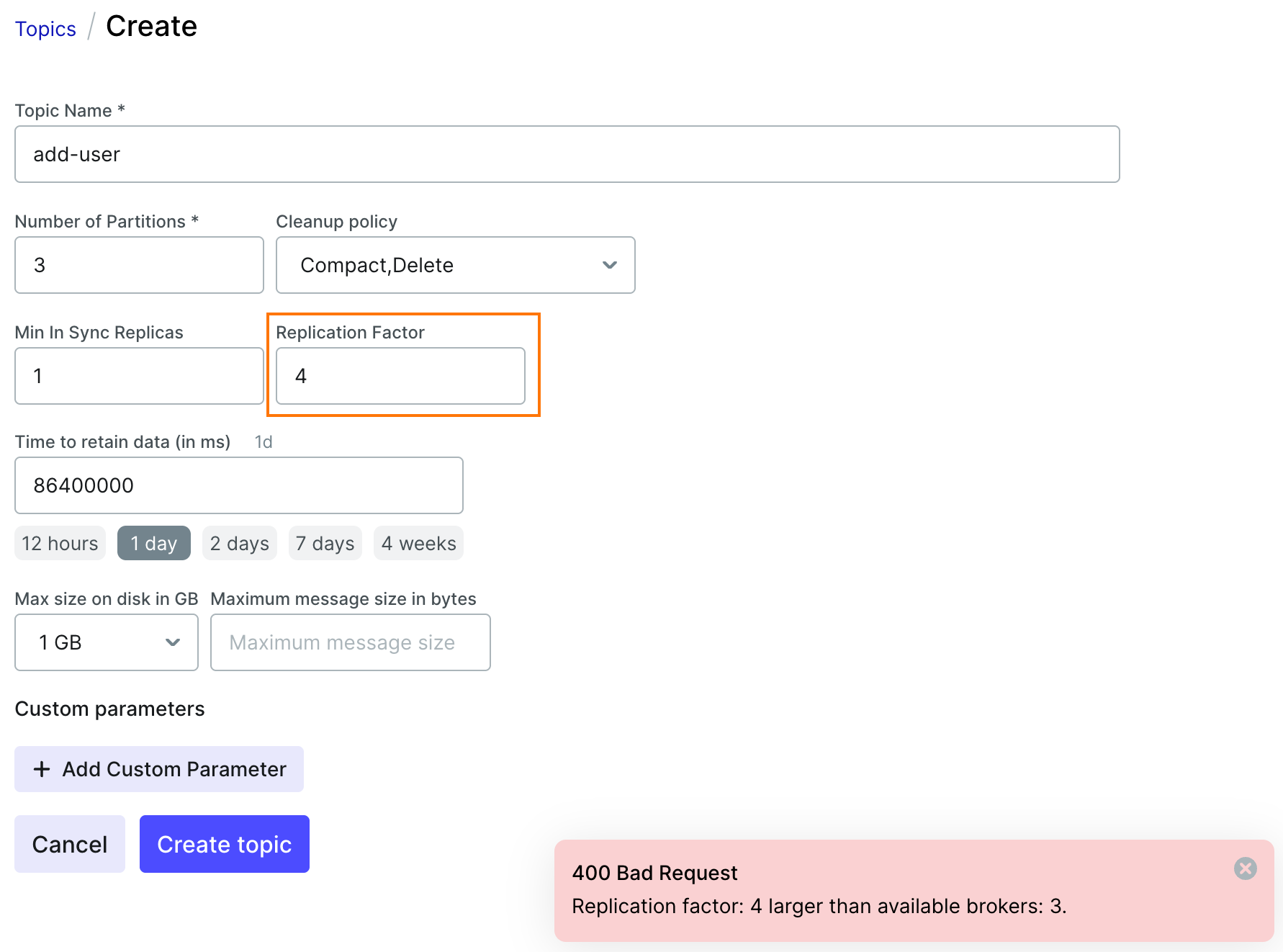
- 副本数(2) < Broker数(3) ===> Topic 创建成功
- Replicas列,第一个绿色数字表示Leader所在的Broker
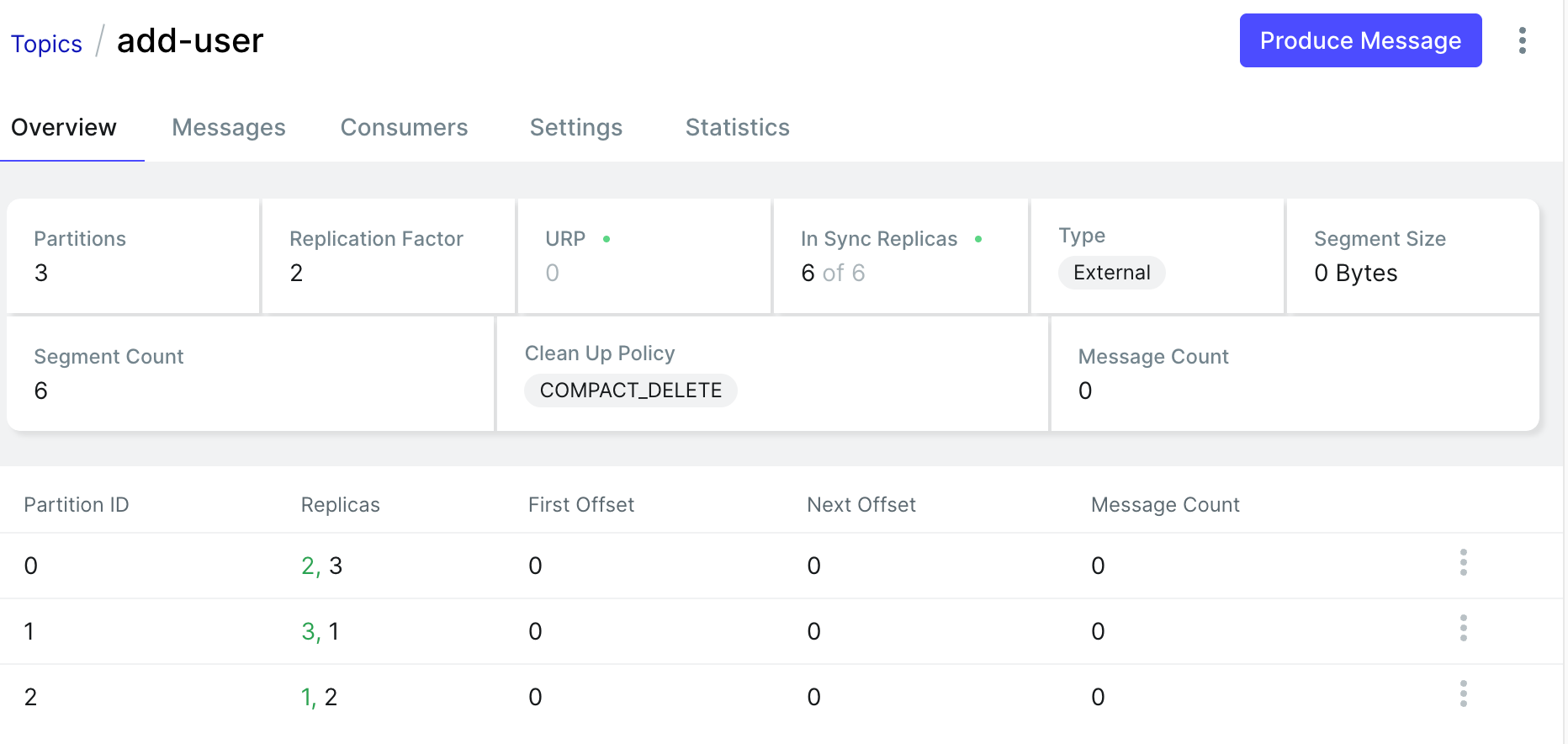
4.3 生产 Message
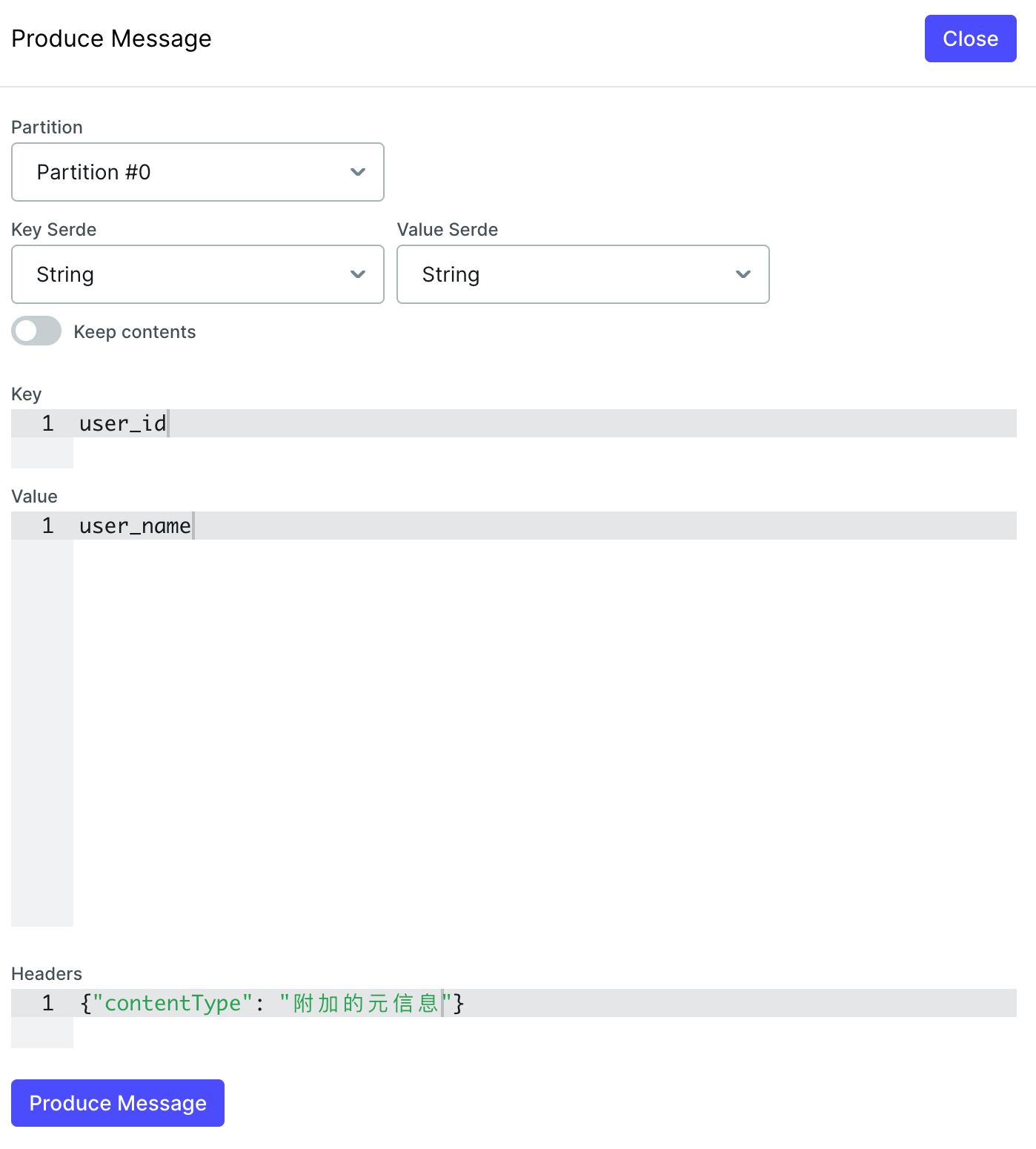
发送消息时并不强制要求指定 Partition,生产者可根据业务需求选择是否显式指定。
- 不指定 Partition 时的默认策略,Kafka 提供了多种自动分区分配策略:
- 基于 Key 的哈希分配(Key-Ordering)
- 若消息包含 Key,则通过 Murmur2 哈希算法对 Key 进行哈希计算,将相同 Key 的消息分配到同一 Partition,保证同一业务实体的消息顺序性。
- 适用场景:需顺序消费的场景(如订单状态更新、用户行为追踪)
- 轮询策略(Round-Robin)
- 若消息未指定 Partition 且无 Key,Kafka 默认按 轮询方式 将消息均匀分配到所有可用 Partition。
- 特点:负载均衡性好,适合高吞吐场景
- 粘性分区策略(Sticky Partitioning)
- Kafka 2.4+ 引入的优化策略:在无 Key 且未指定 Partition 时,优先将消息批量填充到同一 Partition 的批次中,待批次满后切换至另一 Partition。
- 优势:减少未满批次数量,降低延迟并提升吞吐量
- 基于 Key 的哈希分配(Key-Ordering)
Broker 状态
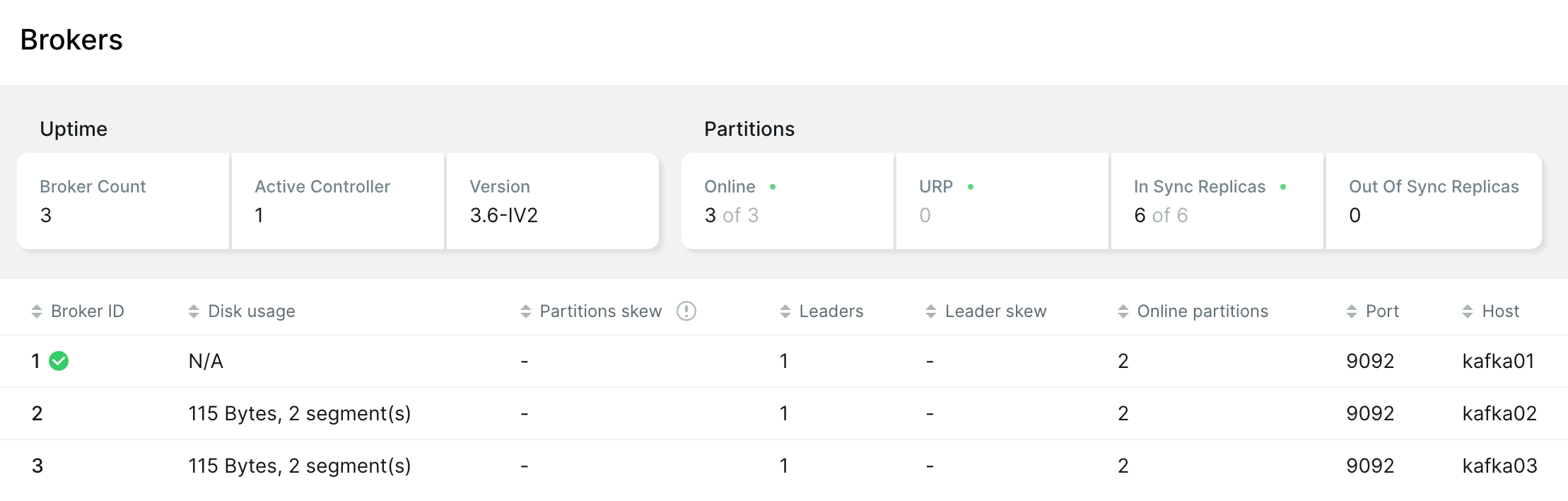
- Broker ID 为 1 的节点是 Controller 节点,负责管理和维护集群状态
- 每个 Broker 上都有 1 个 Leader 副本,2 个在线的 Partition
Controller 选举
- 把 kafka01 容器下线,重新选举 kafka02 为新的 Controller
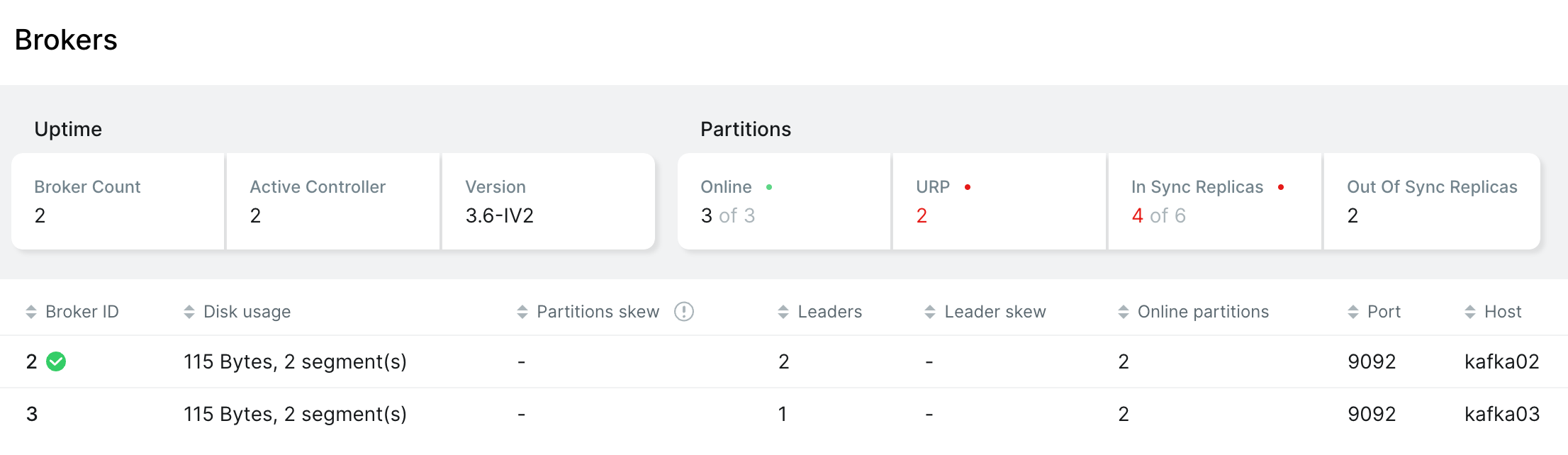
- kafka01 重新上线,Controller依然是 kafka02
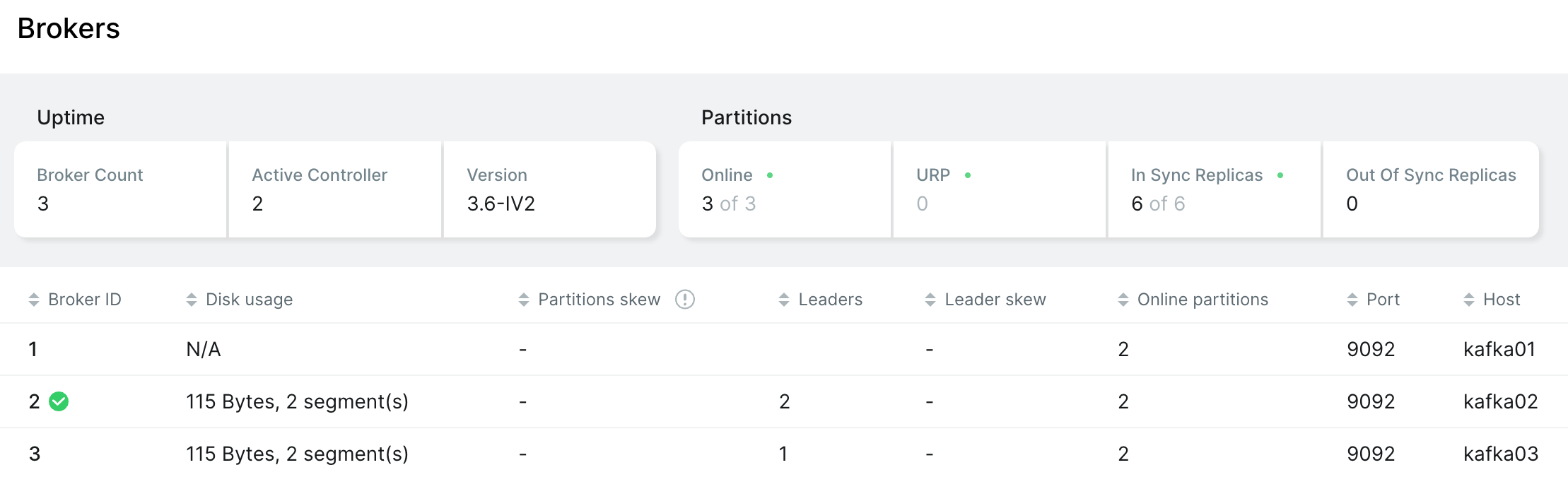
Reference
[1] Kafka Broker, Kafka Topic, Consumer and Record Flow in Kafka
[2] Kafka Consumers
[3] Kafka基础
[5] Kafka权威指南
[6] Kafka文件存储机制