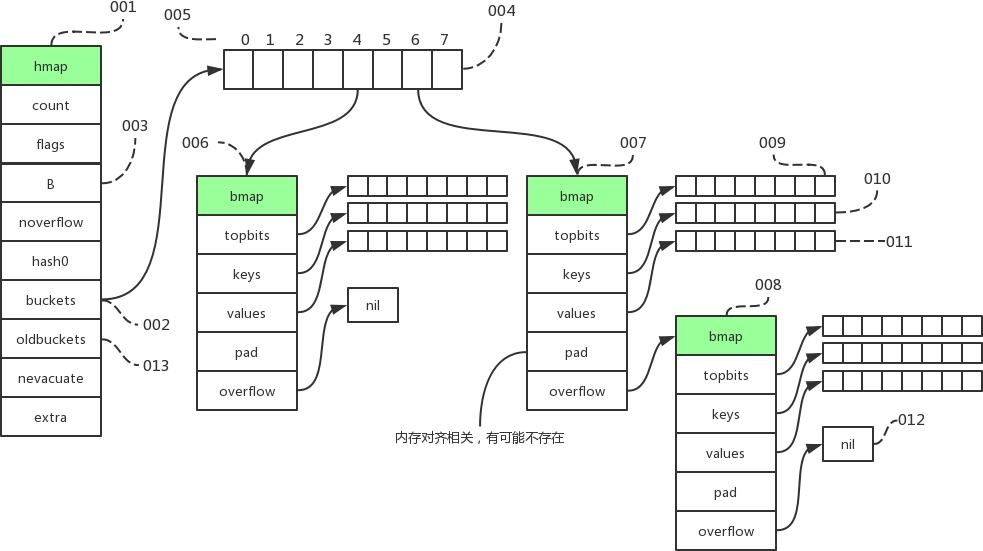
Go数据类型-数组&切片
参考
《Go语言底层原理剖析》第6、7章
《Go专家编程》第1章
《Go语言学习笔记》第5章
《Go语言高级编程》第1章
《Go语言设计与实现》第3章
数组和切片作为Go中的基础数据类型,使用十分频繁。一般在处理函数参数时,切片用的比较多,因为Go是值传递,如果参数是数组那么会把数组复制一遍,开销比较大,如果参数是切片只会把切片结构体复制一遍,开销就很小了。
切片的底层是数组,只不过增加了容量和长度两个属性。下面分别介绍数组以及切片的使用方法以及底层实现原理。
1 数组
1.1 声明方式
package main
import (
"fmt"
"unsafe"
)
func main() {
// 两种声明方式
var arr1 [3]int // 指定长度
var arr2 = [3]int{1, 2, 3} // 指定长度
arr3 := [...]int{4, 5, 6} // 推断长度
fmt.Printf("arr1: %p %T -> %v\n", &arr1, arr1, arr1)
fmt.Printf("arr2: %p %T -> %v\n", &arr2, arr2, arr2)
fmt.Printf("arr3: %p %T -> %v\n", &arr3, arr3, arr3)
fmt.Println(unsafe.Sizeof(arr1), unsafe.Sizeof(arr2), unsafe.Sizeof(arr3))
fmt.Println(unsafe.Sizeof(int(10)))
fmt.Println(len(arr3)) // 可以通过len得到数组的长度
}
// arr1: 0xc0000180c0 [3]int -> [0 0 0]
// arr2: 0xc0000180d8 [3]int -> [1 2 3]
// arr3: 0xc0000180f0 [3]int -> [4 5 6]
// 24 24 24
// 8
// 3
数组的声明方式主要有两种,都会产生一个固定长度的相同元素排列,且每一个元素的物理地址都是相邻的。
如上述例子中,每个数组的长度是 3,所占用的空间都是连续的 24 个字节。这是因为int类型本质上是int64,占用64/8=8个字节,三个int就是 24 字节。
可以通过len得到数组的长度,关于len的细节参考这篇blog:https://tpaschalis.github.io/golang-len/
1.2 数组复制
var arr1 = [3]int{1, 2, 3}
fmt.Printf("arr1: %p %T -> %v\n", &arr1, arr1, arr1)
copyArray(arr1)
fmt.Printf("arr1: %p %T -> %v\n", &arr1, arr1, arr1)
// arr1: 0xc0000b6000 [3]int -> [1 2 3]
// a: 0xc0000b6060 [3]int -> [1 123 3] 与arr1地址不同
// arr1: 0xc0000b6000 [3]int -> [1 2 3]
Go语言中的数组在赋值和函数调用时的形参都是值复制,在函数中修改数组实际上是修改数组副本。
1.3 实现原理
1.3.1 创建数组
func NewArray(elem *Type, bound int64) *Type {
if bound < 0 {
Fatalf("NewArray: invalid bound %v", bound)
}
t := New(TARRAY)
t.Extra = &Array{Elem: elem, Bound: bound}
t.SetNotInHeap(elem.NotInHeap())
return t
}
编译期间的数组类型是由上述的/src/cmd/compile/internal/types.NewArray 函数生成的,该类型包含两个字段,分别是元素类型 Elem 和数组的大小 Bound,这两个字段共同构成了数组类型,而当前数组是否应该在堆栈中初始化也在编译期就确定了。
1.3.2 数组初始化
Go 语言的数组有两种不同的创建方式,一种是显式的指定数组大小,另一种是使用 [...]T 声明数组,Go 语言会在编译期间通过源代码推导数组的大小,将后一种转换为前一种。
- 指定数组大小:使用上面提到的
NewArray进行初始化。 - 不指定数组大小:编译器会在对该数组的大小进行推导,通过遍历元素的方式来计算数组中元素的数量。
func typecheckcomplit(n *Node) (res *Node) {
...
if n.Right.Op == OTARRAY && n.Right.Left != nil && n.Right.Left.Op == ODDD {
n.Right.Right = typecheck(n.Right.Right, ctxType)
if n.Right.Right.Type == nil {
n.Type = nil
return n
}
elemType := n.Right.Right.Type
// 通过遍历元素的方式来计算数组中元素的数量
length := **typecheckarraylit**(elemType, -1, n.List.Slice(), "array literal")
n.Op = OARRAYLIT
n.Type = types.NewArray(elemType, length)
n.Right = nil
return n
}
...
switch t.Etype {
case TARRAY:
typecheckarraylit(t.Elem(), t.NumElem(), n.List.Slice(), "array literal")
n.Op = OARRAYLIT
n.Right = nil
}
}
这个删减后的 cmd/compile/internal/gc.typecheckcomplit 会调用 cmd/compile/internal/gc.typecheckarraylit 通过遍历元素的方式来计算数组中元素的数量。
对于一个由字面量组成的数组,根据数组元素数量的不同,编译器会在负责初始化字面量的 cmd/compile/internal/gc.anylit 函数中做两种不同的优化:
- 当元素数量小于或者等于 4 个时,会直接将数组中的元素放置在栈上;
- 当元素数量大于 4 个时,会将数组中的元素放置到静态区并在运行时取出;
1.3.3 越界检查
数组访问越界是非常严重的错误,Go语言中对越界的判断有一部分是在编译期间类型检查阶段完成的,typecheck1函数会对访问数组的索引进行验证。
具体的验证逻辑如下:
- 访问数组的索引是非整数时报错为
non-integer array index%v。 - 访问数组的索引是负数时报错为
invalid array index%v(index must be non-negative)。 - 访问数组的索引越界时报错为
invalid array index%v(out of bounds for%d-element array)。
2 切片
Go语言程序中很少使用数组,基本上都是用的切片slice。slice的底层还是数组,但是slice的长度是可变的,下面对slice进行介绍。
2.1 声明方式
var slice1 []int // 类似与数组声明,只不过不设定长度
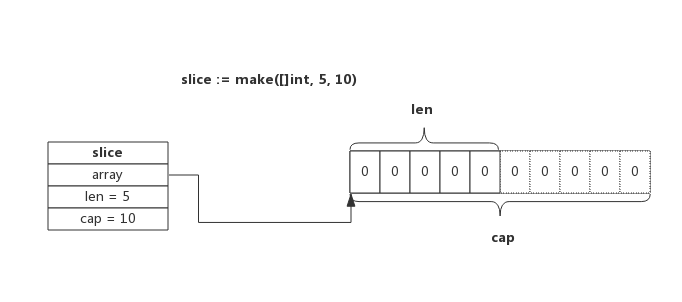
slice2 := make([]int, 5)
slice3 := make([]int, 5, 7) // make(type, len, cap)
slice4 := slice3[1:3]
fmt.Println(slice1, len(slice1), cap(slice1))
fmt.Println(slice2, len(slice2), cap(slice2))
fmt.Println(slice3, len(slice3), cap(slice3))
fmt.Println(slice4, len(slice4), cap(slice4))
// [] 0 0
// [0 0 0 0 0] 5 5
// [0 0 0 0 0] 5 7
// [0 0] 2 6
slice声明有两种方式:
[]int类似与数组声明,只不过不设定长度make(type, len, cap)设定slice的长度和容量,为了减少后面扩容带来的损耗通常一次分配内存。需要注意的是,当长度不等0时会给slice的前len个元素分配默认值,如slice3的前5个元素都是0。
也可以从已有的slice或数组中通过截取 [left:right]的方式获得新的切片(左闭右开),后面详细介绍。
Slice数据结构
slice的结构体定义在 /src/reflect/value.go#L1994 中,包含三个字段:
// SliceHeader is the runtime representation of a slice.
// It cannot be used safely or portably and its representation may
// change in a later release.
// Moreover, the Data field is not sufficient to guarantee the data
// it references will not be garbage collected, so programs must keep
// a separate, correctly typed pointer to the underlying data.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
Data指向底层的数组,Len为切片长度,Cap为切片容量。
2.2 切片截取
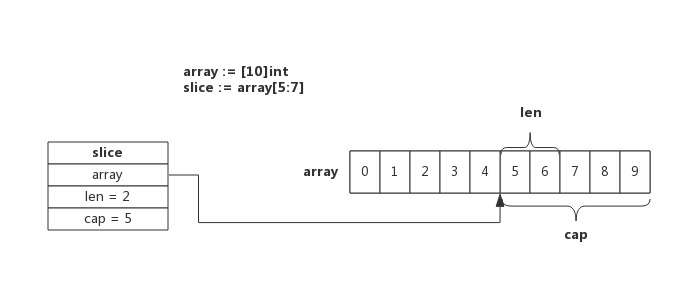
slice1 := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} // slice
array := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} // array
slice2 := slice1[5:7]
slice3 := array[5:7]
fmt.Println(slice2, len(slice2), cap(slice2))
fmt.Println(slice3, len(slice3), cap(slice3))
// [5 6] 2 5
// [5 6] 2 5
切片截取可以从切片里截也可以从数组里截,截取的规则遵循左闭右开,例如上面 [5:7] 表示从下标为 5 到 下标为6,不包括下标为 7 的元素。
不难理解截取出来的 slice 长度为 2,但是为什么容量 cap 等于 5 呢?这是因为截取的 slice 依然是指向被截取的 slice 或 array,二者底层共用一个数组。
slice1 := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice2 := slice1[5:7]
fmt.Println(slice2, len(slice2), cap(slice2))
slice1[6] = 10
slice1 = append(slice1, 10)
fmt.Println(slice1, len(slice1), cap(slice1))
fmt.Println(slice2, len(slice2), cap(slice2))
// [5 6]
// [0 1 2 3 4 5 10 7 8 9 10] 11 20
// [5 10] 2 5
slice1 := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice2 := slice1[5:7:8] // [start:end:cap] 设置切片的容量
fmt.Println(slice2, len(slice2), cap(slice2))
// [5 6] 2 3
如上修改原切片里的元素,截取出来的切片能够感知到该切片的改动,说明二者共用一个底层。可以观察到 slice1 在 append 一个元素后其 cap 变成了 20,而 slice2 的 cap 还是 5。
这就涉及到 slice 的扩容机制了,在这种情况下, slice 的 cap 翻倍并且指向一个新的底层数组,但是 slice2 还是指向原来的底层数组。
2.3 扩容
slice的扩容机制其实很简单,对于一个 slice ,如果其len<cap说明还有空间可以存放新的元素,直接放进 slice 即可。但是如果len==cap,则说明没有空间了即需要扩充容量。
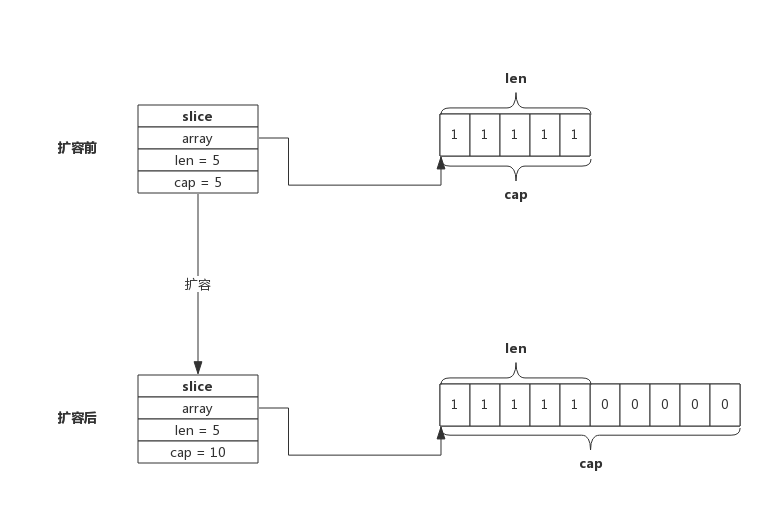
src/runtime/slice.go#L125 中实现了扩容机制:
func growslice(et *_type, old slice, cap int) slice {
...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
...
}
扩容操作只关心容量,会把原Slice数据拷贝到新 Slice,追加数据由 append 在扩容结束后完成。上图可见,扩容后新的 Slice 长度仍然是 5,但容量由 5 提升到了 10,原 Slice 的数据也都拷贝到了新 Slice 指向的数组中。
扩容容量的选择遵循以下规则:
- 如果原Slice容量小于 1024,则新Slice容量将扩大为原来的 2 倍;
- 如果原Slice容量大于等于 1024,则新Slice容量将扩大为原来的 1.25 倍;
使用append()向Slice添加一个元素的实现步骤如下:
- 假如 Slice容量够用,则将新元素追加进去,Slice.len++,返回原 Slice
- 原 Slice 容量不够,则将 Slice 先扩容,扩容后得到新 Slice
- 将新元素追加进新 Slice,Slice.len++,返回新的 Slice
上述代码片段仅会确定切片的大致容量,下面还需要根据切片中的元素大小对齐内存,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会对齐内存。
2.4 深拷贝
复制的切片不会改变指向底层的数据源,但有些时候我们希望建一个新的数组,并且与旧数组不共享相同的数据源,这时可以使用copy函数。
slice1 := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice2 := make([]int, len(slice1), cap(slice1))
fmt.Println(slice2)
copy(slice2, slice1)
slice1[5] = 10
fmt.Println(slice2)
// [0 0 0 0 0 0 0 0 0 0]
// [0 1 2 3 4 5 6 7 8 9]