参考
MySQL索引【编程不良人】
高性能MySQL第5章 - 创建高性能的索引
B树、B+树详解
1. 索引基础
索引诞生的主要目的就是加速数据的查询,MySQL的索引类似于书的目录,通过目录可以快速找到页码,从而快速定位内容。除此之外,索引大大减少了机器需要扫描的数据量,可以将随机I/O变为顺序I/O。索引也是有缺点的:维护索引会消耗数据库资源包括空间资源和时间资源。
不同的数据库会在优缺点之间权衡,根据其适合的业务场景调整索引的结构。下面的介绍针对主流的MySQL的InnoDB引擎展开。
2. 索引分类
常用的InnoDB引擎主要支持四种索引:
- 主键索引
- 唯一索引
- 单值索引
- 复合索引
2.1 主键索引
将某字段设置为主键后,数据库会对该主键自动建立索引。若不设置主键则不会自动建立主键索引。
-- 创建数据表,不设置主键 --
create table user1(
id varchar(10),
name varchar(20),
age int
);
-- 查看主键 --
show index from user1;
-- 创建数据表,设置主键 --
create table user2(
id varchar(10) primary key,
name varchar(20),
age int
);
-- 查看主键 --
show index from user2;

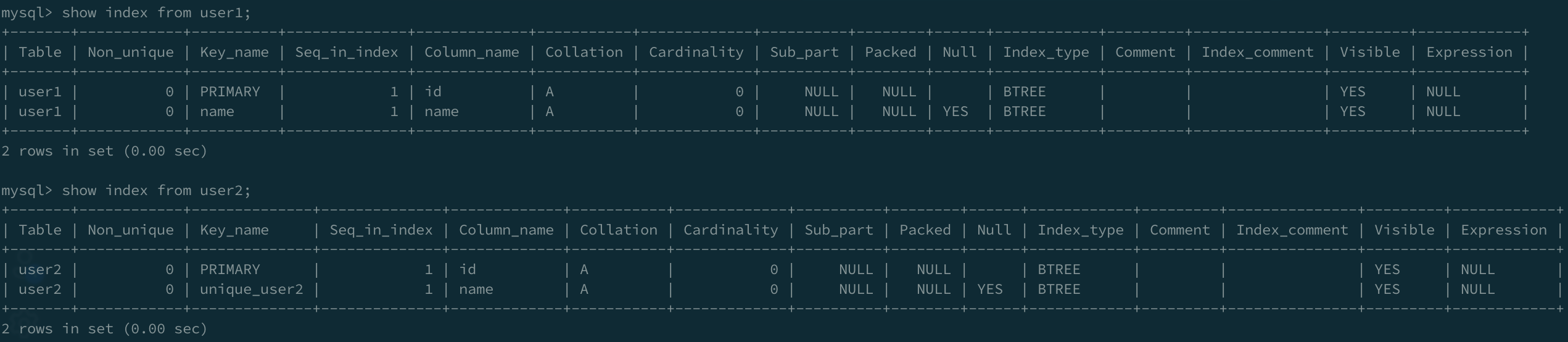
user1没有设置主键,因此没有索引。user2设置主键为id,自动对id建立了主键索引。图中可以看到Key_name为PRIMARY表示这是一个主键索引。
2.2 唯一索引
与主键索引相同的是索引列的值必须唯一,不同的是主键索引列不允许空值,而唯一索引列允许有空值。
-- 建表时创建唯一索引,unique(column_name1), unique(column_name2) ... --
create table user1(
id varchar(10) primary key,
name varchar(20),
age int,
unique(name)
);
-- 建表后创建唯一索引 --
create table user2(
id varchar(10) primary key,
name varchar(20),
age int
);
create unique index unique_user2 on user2(name);
-- 删除索引 --
drop unique index 索引名 on 表名;
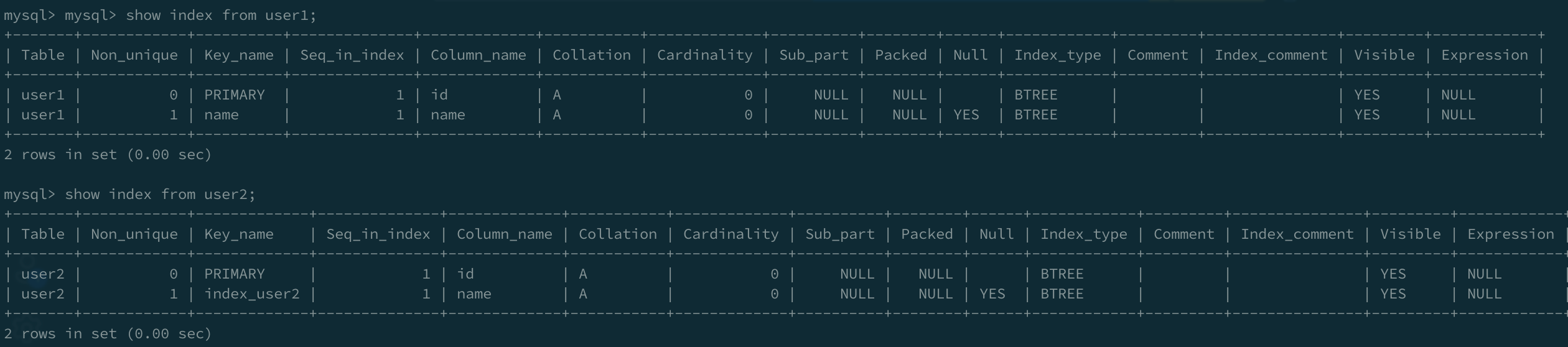
通过create unique index语句创建索引,可以自定义索引的名称。索引列的值必须唯一,所以Non_unique为0。
2.3 单值索引
单值索引也称单列索引、普通索引。一个索引只包含单个列,一个表可以有多个单值索引。
-- 建表时创建单值索引,key(column_name1), key(column_name2) ... --
create table user1(
id varchar(10) primary key,
name varchar(20),
age int,
key(name)
);
-- 建表后创建单值索引 --
create table user2(
id varchar(10) primary key,
name varchar(20),
age int
);
create index index_user2 on user2(name);
-- 删除索引 --
drop index 索引名 on 表名;
通过create index语句创建索引,可以自定义索引的名称。索引列的值不用唯一,所以Non_unique为1。单值索引列允许为空,所以Null为YES。
2.4 复合索引
一个索引包含多个列。
-- 建表时创建复合索引,key(column_name1, column_name2 ...) --
create table user1(
id varchar(10) primary key,
name varchar(20),
age int,
key(name, age)
);
-- 建表后创建复合索引 --
create table user2(
id varchar(10) primary key,
name varchar(20),
age int
);
create index index_user2 on user2(name, age);
-- 删除索引 --
drop index 索引名 on 表名;
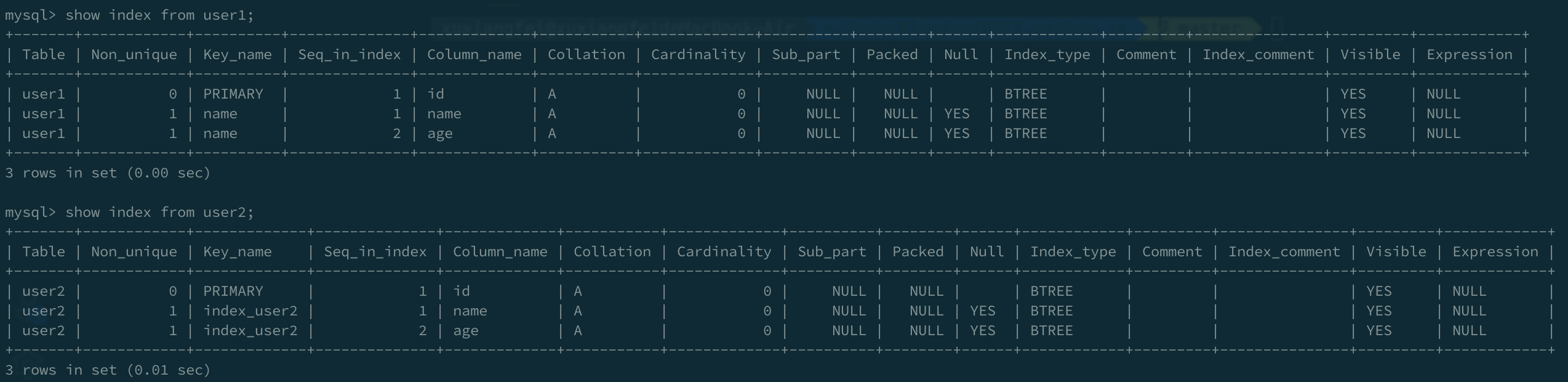
Seq_in_index表示索引列在索引中的顺序。
2.4.1 最左前缀原则
创建复合索引时基于name和age字段,在查询时要遵循最左前缀原则,即必须复合最左前缀的顺序采用使用复合索引。 同时MySQL还做了一个优化,引擎在查询时为了更好利用索引,在查询过程中会动态调整查询字段顺序。
假设现在创建复合索引语句为:create index index_name on user(name, age, tel),查询时:
- name age tel 可以利用索引,符合最左前缀原则
- name tel age 可以利用索引,动态调整字段顺序后符合最左前缀原则
- age tel 不可以利用索引
- tel age name 可以利用索引,动态调整字段顺序后符合最左前缀原则
- tel name 不可以利用索引
3. 索引底层原理
首先观察下面的例子,插入无序的数据。
create table user(
id varchar(10) primary key,
name varchar(20),
age int
);
insert into user values(3, 'Tim', 18);
insert into user values(7, 'Tom', 14);
insert into user values(2, 'Bob', 31);
insert into user values(1, 'Andy', 18);
insert into user values(4, 'John', 24);
insert into user values(9, 'Jodan', 11);
insert into user values(6, 'Kobe', 10);
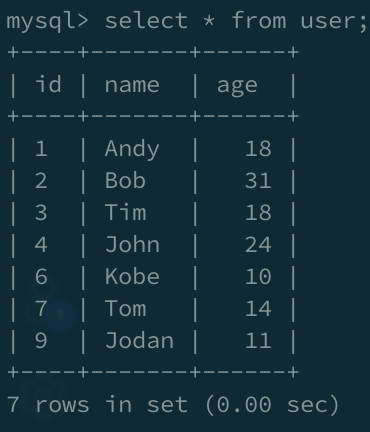
在输出时,会按照主键的大小顺序输出。索引的底层实现决定了这种现象,下面介绍一下索引底层原理。
3.1 B+树
MySQL 的 InnoDB 引擎使用 B+树 作为索引的数据结构,这是一种基于B树的改进。关于B-tree和B+tree的解释可以参考下面的博客。
B+树是为磁盘或其他直接存取辅助设备设计的一种平衡查找树,在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点,各叶子节点通过指针进行链接,形成一个链表。如下图所示,其高度为2,每页可存放4条记录,扇出(fan out)为5:
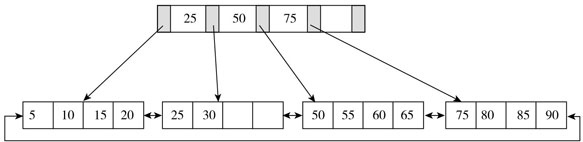
B树的非叶子节点也可以存放数据,意味着每一页可放置的记录条数更少。当数据量很大时,B树的深度较大,查询时磁盘的I/O次数也会更多,进而会影响查询效率。
而B+树的数据是按照被索引字段,顺序存放在叶子节点的,非叶子节点只寸被索引字段和指针,可以放置的记录条数更多。上面例子中select * from user实际是对叶子结点链表的遍历,所以是顺序输出的。
在InnoDB存储引擎中,每个页的大小为16KB。B+树的高度一般都在2~4层,这意味着查找某一键值最多只需要2到4次IO操作,这还不错。因为现在一般的磁盘每秒至少可以做100次IO操作,2~4次的IO操作意味着查询时间只需0.02~0.04秒。
3.2 聚簇索引 vs 非聚簇索引
- 聚簇索引:将索引与数据存储到一起,索引结构的叶子结点保存了行数据。聚簇索引指的不一定就是主键索引,但主键索引一定是聚簇索引。
- **非聚簇索引(辅助索引)**:将索引与数据分开存储,索引结构的叶子结点指向了数据对应的位置。非聚簇索引存储的不再是行的物理位置,而是主键值,非聚簇索引访问数据总是需要二次查找。
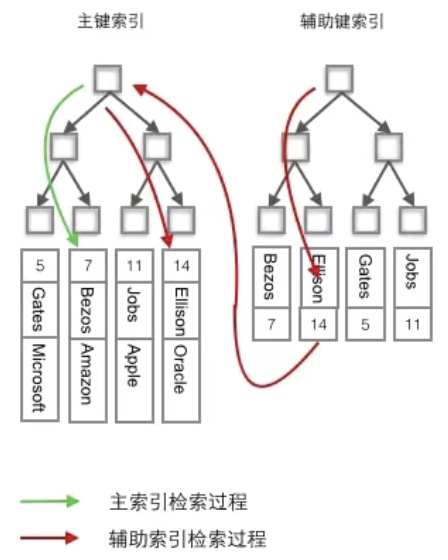
聚簇索引默认是主键,如果表中没有定义主键,InnoDB会选择一个唯一且非空的索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键(类似oracle中的Rowld)来作为聚簇索引。如果已经设置了主键为聚簇索引又希望再单独设置聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
4. 面试常见问题
4.1 聚簇索引需要注意什么?
- 当使用主键为聚簇索引时,主键最好不要使用uuid,因为uuid的值太过离散,不适合排序且可能出现新增加记录的 uuid,会插入在索引树中间的位置,导致索引树调整复杂度变大,消耗更多的时间和资源。
- 建议使用int类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小。而且,主键值占用的存储空间越大,辅助索引中保存的主键值也会跟着变大,占用存储空间,也会影响到IO操作读取到的数据量。
4.2 为什么主键通常建议使用自增id?
- 聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增,那么可以想象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
4.3 什么情况下无法利用索引呢?
- 查询语句中使用LIKE关键字
在查询语句中使用LIKE关键字进行查询时,如果匹配字符串的第一个字符为“%”,索引不会被使用。如果“%”不是在第一个位置,索引就会被使用。 - 查询语句中使用多列索引
多列索引是在表的多个字段上创建一个索引,只有查询条件中使用了这些字段中的第一个字段,索引才会被使用。 - 查询语句中使用OR关键字
查询语句只有OR关键字时,如果OR前后的两个条件的列都是索引,那么查询中将使用索引。如果OR前后有一个条件的列不是索引,那么查询中将不使用索引。